


Guides19 min read
Skills vs MCP: What's the Difference and When to Use Each
The foundational breakdown of tools, MCP, and skills — start here if this guide is your first stop.
Sawyer Middeleer
Guide
Duet Team

Six months ago, "extending Claude" meant either writing custom MCP servers or stuffing everything into a 5,000-line CLAUDE.md file. Then Anthropic shipped Claude Code Skills in October 2025, open-sourced the format that December, and within weeks OpenAI had adopted the same SKILL.md spec for Codex and ChatGPT. Suddenly there was a portable, model-invoked way to teach any coding agent how your team actually works.
Skills have quietly become the most important primitive in Claude Code. They're the difference between an assistant that needs hand-holding through every workflow and one that knows your repo conventions, your review checklist, your deployment dance, and a hundred other things you'd otherwise have to repeat in every prompt. Even better: they're cheap. A skill costs about 100 tokens of context until Claude decides it's needed, meaning you can have fifty skills installed and pay almost nothing for the ones you aren't using right now.
But the ecosystem is moving fast, and there's confusion about what skills actually are, how they differ from MCP servers and subagents, what goes in the SKILL.md file, and how teams should organize them. This guide is the canonical answer.
We'll cover what a Claude Code skill is, how it compares to MCP and subagents (with a real decision matrix), the SKILL.md format down to the YAML frontmatter, a concrete 5-minute build of your first skill, the best practices that separate skills people actually invoke from skills that gather dust, how to share skills across a team so they compound instead of fragment, and where to find and install skills from the community.
A Claude Code Skill is a folder of instructions, scripts, and resources that Claude loads on demand to perform a specialized task in a repeatable way. Each skill lives in a directory containing a single SKILL.md file with YAML frontmatter (a name and description) and markdown instructions Claude follows when the skill is activated. Optional helper scripts, reference files, and templates can sit alongside it.
In one sentence, a skill is procedural knowledge — a reusable "how we do XYZ here" — packaged in a format Claude can discover and load itself.

SKILL.md body (typically under 5,000 tokens) into context. You don't have to invoke it manually — skills are model-invoked by default.This is the most important thing to understand about Claude Code Skills:
/deploy and Claude runs it.That's why the description field in YAML frontmatter matters so much. It's not documentation — it's the trigger. Claude is reading your description on every turn and asking, "Does the user's request match this?" A vague description means a skill that never fires. A precise one means the skill activates exactly when it should.
Almost anything you'd otherwise repeat in a system prompt or paste into chat:
A skill can also bundle scripts (Python, Bash, Node, whatever runtime is available in the environment), reference files Claude should read on demand, and even other skills it composes with.
Anthropic released the Agent Skills specification as an open standard in December 2025. The same SKILL.md format now works across:
Build a skill once, run it anywhere your team uses an agent. This portability is part of why skills have moved from "neat feature" to "default way to extend an agent" so fast.
People mix these three up all the time:
| CLAUDE.md | Skills | Prompts | |
|---|---|---|---|
| Loading | Always loaded every session | On demand (model-invoked) | Re-entered each time |
| Token cost | Full file size, every session | ~100 tokens idle, ~5K active | Paid per message |
| Best for | Global project conventions | Repeatable, context-specific workflows | One-off instructions |
| Scope | Project or user-wide | A specific task or workflow | Single conversation |
CLAUDE.md is always loaded. A skill is loaded when needed. That distinction is why a 50-skill library doesn't slow Claude down, but a 5,000-line CLAUDE.md does.
Three things converged in late 2025:
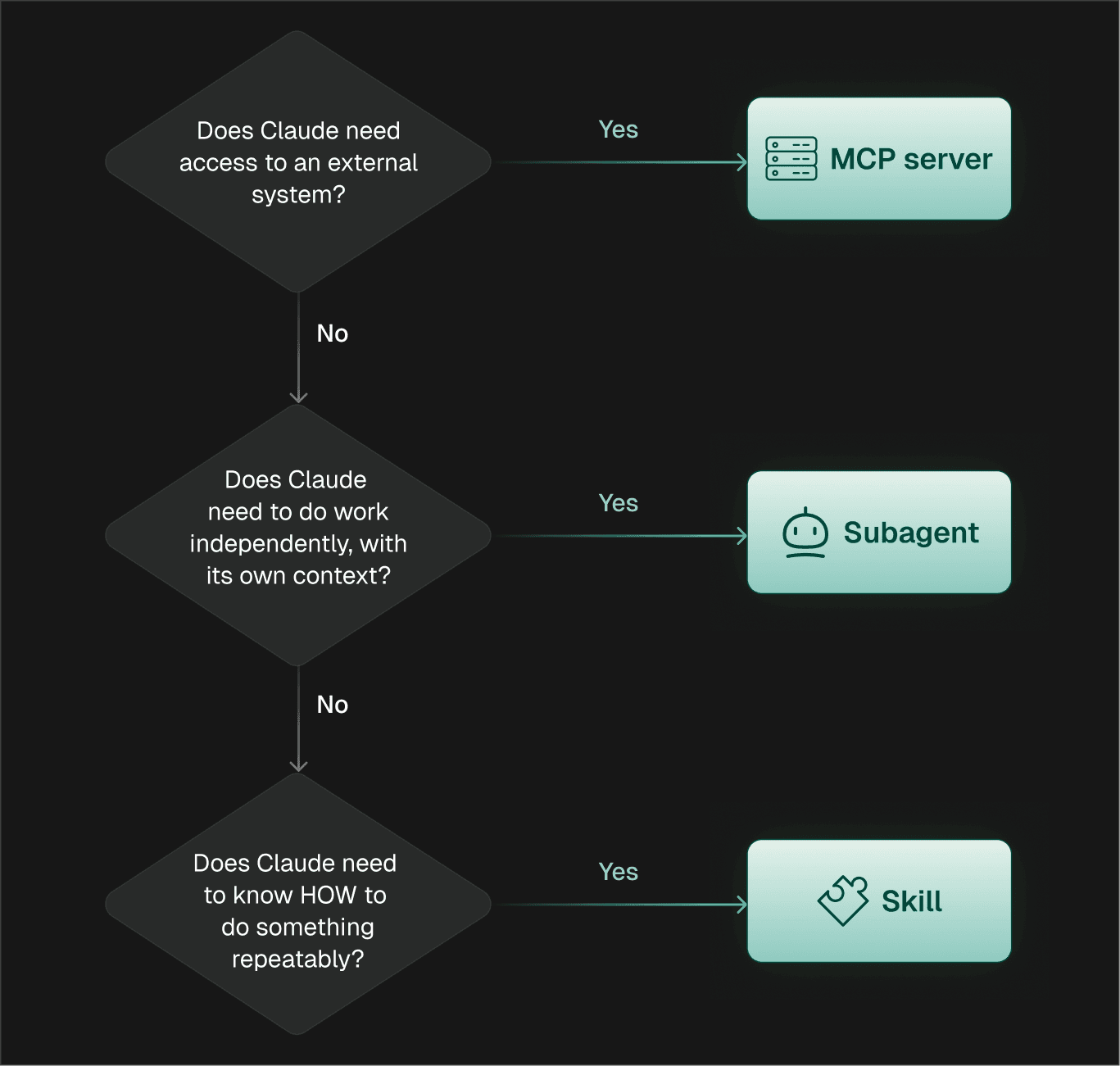
Short answer: use Skills for how to do something, MCP for access to external systems, and Subagents for delegating work to a specialist with its own context. Most production setups use all three. The trick is knowing which mechanism fits which problem — picking wrong inflates context cost, slows your sessions, and creates maintenance debt.
| Skills | MCP Servers | Subagents | |
|---|---|---|---|
| What it does | Teaches Claude how to perform a task | Connects Claude to external systems | Runs specialized work with its own context |
| Context cost | ~100 tokens idle, ~5K when active | ~10K+ per server (always loaded) | Own context window, separate from main session |
| Best for | Procedural knowledge, team conventions | APIs, databases, browsers, file systems | Async work, long research, parallel tasks |
| Example | PR review checklist | GitHub MCP, Postgres, Slack | Code-reviewer agent on Sonnet |
| Who invokes it | Claude (model-invoked) | Claude (on demand with Tool Search) | You or Claude (delegation) |
Pick a skill when Claude needs procedural knowledge — a way of doing something — that should activate based on context.
Good fits:
Skills shine when the same workflow repeats across many sessions and you don't want to re-explain it each time.
Pick MCP when Claude needs access to a system it can't reach on its own — APIs, databases, third-party tools, your file system over SSH, a browser.
Good fits:
The catch: MCP is expensive in context. A typical 5-server setup with 58 tools eats roughly 55,000 tokens before you've sent a single prompt. Anthropic's Tool Search feature cuts this by ~85% by loading tool definitions on demand, but it's still the heaviest of the three primitives. Add MCP servers deliberately, not casually.
Pick a subagent when you need a specialist with isolation — its own context window, its own tools, sometimes a different model.
Good fits:
Subagents matter when the work should happen out of band — long research, parallel exploration, anything that would otherwise crowd out your main conversation.
When you're not sure which one to reach for, walk this in order:
Say you want Claude to review pull requests against your team's standards.
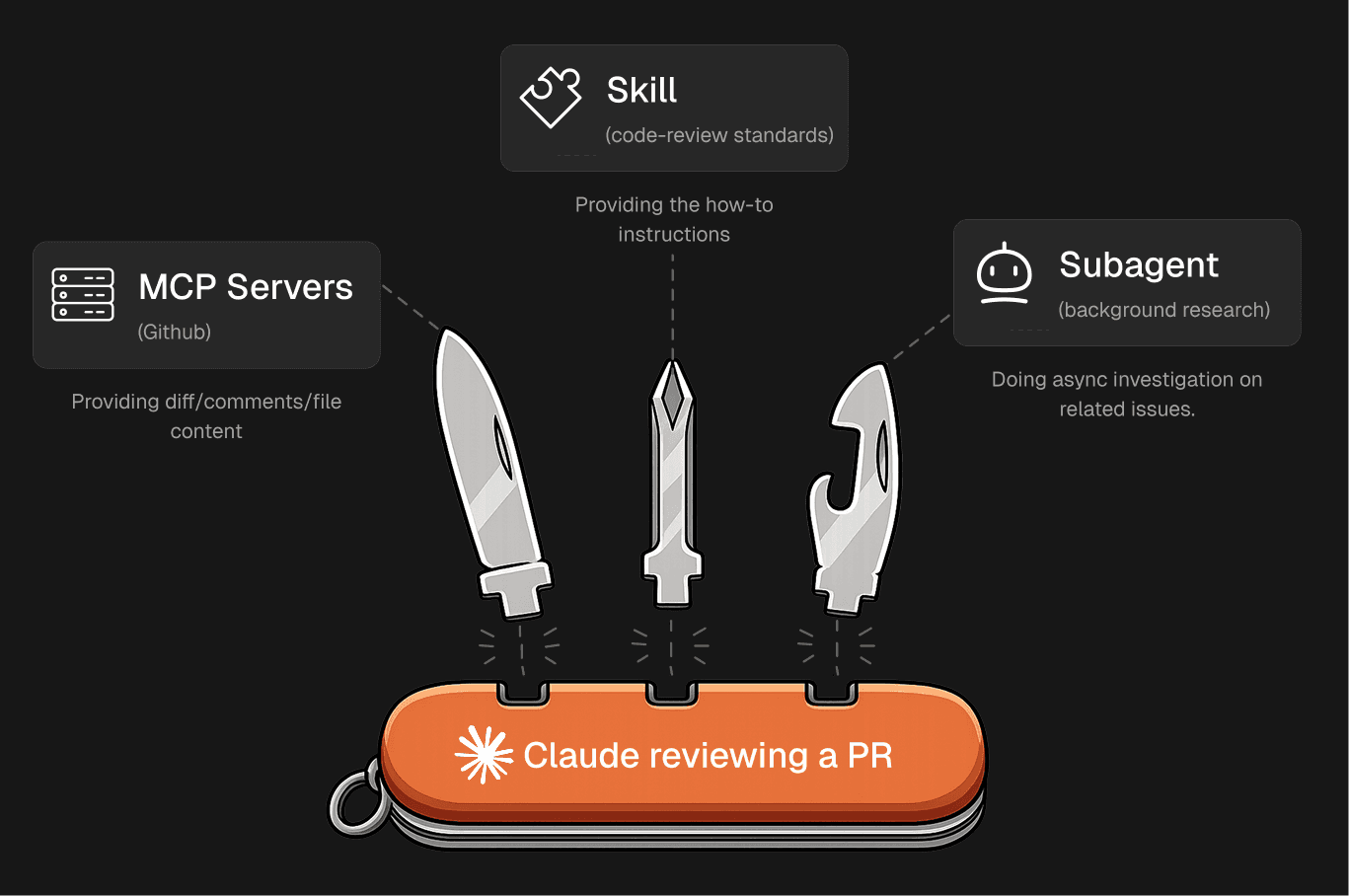
code-review-checklist — the team's review conventions (security, naming, test coverage, PR description format).pr-reviewer — runs on Sonnet, has read-only tools, isolated context. It calls the GitHub MCP to fetch the PR, loads the code-review-checklist skill for the methodology, posts comments via MCP, and returns a summary to the main session.Three primitives, one specialist. None of them duplicate each other.
Plugins are the distribution format. A plugin can bundle skills, subagents, MCP server configs, hooks, and slash commands into one installable package. If you're sharing capabilities across a team or open-sourcing them to the community, plugins are how you ship.
Most production Claude Code setups end up with:
If you've got more skills than MCP servers, you're probably doing it right. If you've got more MCP servers than skills, you're paying a context tax for capabilities you could express more cheaply.
YAML frontmatter and progressive disclosure explained
A SKILL.md file has two parts: YAML frontmatter between --- markers that tells Claude when to use the skill, and markdown instructions that tell Claude how. That's the entire spec.
Everything else — scripts, references, templates — is optional and lives in the same folder.
---
name: my-skill
description: A clear description of what this skill does and when to use it.
---
# My Skill
Instructions Claude follows when this skill is active.
Drop that file in ~/.claude/skills/my-skill/SKILL.md and Claude Code will pick it up on next launch.
The frontmatter sits between --- markers at the top of the file.
| Field | Required? | What it does |
|---|---|---|
name | Recommended | Unique identifier. Shows up in skill lists and plugin manifests. |
description | Strongly recommended | The trigger signal. Claude reads this to decide whether to load the skill. |
disable-model-invocation | Optional | Set true to require explicit invocation. Default: false. |
allowed-tools | Optional | Restricts which tools the skill can use while active. |
Example with all fields:
---
name: api-error-handler
description: Use when reviewing or writing API endpoints that need consistent error handling. Covers status codes, error envelope format, and retry semantics for our internal services.
disable-model-invocation: false
allowed-tools: Read Grep Edit
---
When a session starts, Claude scans every installed skill's frontmatter — name + description — costing roughly 100 tokens per skill. That's the entire idle footprint.
The skill body, scripts, and any reference files don't load until Claude decides the skill is relevant.
Claude makes that decision by matching your prompt against each skill's description. So the description has two jobs:
A description like "Helper for emails" will rarely fire. A description like "Use when drafting customer-facing email replies. Applies our brand voice (warm, direct, no jargon) and our standard sign-off format." will fire exactly when it should.
Rule of thumb: if you can't read your description and immediately know when to invoke the skill, neither can Claude.
Progressive disclosure is the layered loading system that makes skills cheap:
| Tier | What loads | Token cost |
|---|---|---|
| Discovery | name + description from YAML | ~100 tokens/skill |
| Activation | Full SKILL.md body | ~1K–5K tokens |
| Execution | Scripts, reference files, templates | Only what the task needs |
This is why you can have 50 skills installed and barely notice the overhead. Compare that to MCP, where every connected server pays its full token cost on every session whether you use it or not.
A real-world skill folder usually looks like this:
~/.claude/skills/document-reader/
├── SKILL.md # Main instructions (under 500 lines)
├── examples.md # Usage examples Claude reads on demand
├── reference/
│ └── pdf-quirks.md # Edge cases, loaded only when relevant
└── scripts/
└── convert.py # Helper script the skill calls
In the SKILL.md body, you reference the supporting files by relative path. Claude only reads them when the workflow needs them — which is the whole point.
There's no enforced template, but the skills that work best follow a predictable shape:
---
name: skill-name
description: Specific trigger description
---
# Skill Name
One-paragraph summary of what this skill does and when it applies.
## When to use this skill
- Bullet list of trigger scenarios
## When NOT to use this skill
- Counter-cases that look similar but should use a different approach
## Instructions
Step-by-step procedure Claude should follow.
## Examples
Concrete before/after or input/output examples.
## References
- See `reference/edge-cases.md` for unusual situations
- See `scripts/helper.py` for the conversion utility
Anthropic's own guidance: keep the SKILL.md body under 500 lines. If you're approaching that limit, split content into reference files in the same folder and link to them from the body. The body is the always-loaded-when-active layer; reference files are the on-demand layer.
The fastest way to learn Claude Code Skills is to build one. This walkthrough takes about five minutes and gives you a working, model-invoked skill you can extend immediately. We'll build a commit-message skill that generates conventional commit messages from a diff.
Skills live in one of two places:
~/.claude/skills/.claude/skills/ inside the repoFor this walkthrough, we'll go user-level so it's available across every project.
mkdir -p ~/.claude/skills/commit-message
cd ~/.claude/skills/commit-message
touch SKILL.md
Open SKILL.md in your editor and paste this:
---
name: commit-message
description: Use when the user asks for a commit message, asks to commit changes, or wants to summarize a diff. Generates Conventional Commits format (type(scope): subject) with an optional body explaining the why, not the what.
allowed-tools: Bash Read
---
# Commit Message Generator
Generate a Conventional Commits-formatted commit message from the current staged changes.
## When to use this skill
- User says "write a commit message" or "commit this"
- User asks you to summarize a diff
- User wants help drafting a PR title (use the same format)
## When NOT to use this skill
- User wants a free-form changelog or release notes (different format)
- User explicitly asks for a non-Conventional-Commits style
## Instructions
1. Run `git diff --staged` to see the staged changes.
2. If nothing is staged, run `git diff` and warn the user the changes aren't staged yet.
3. Identify the primary change type: `feat`, `fix`, `refactor`, `docs`, `test`, `chore`.
4. Pick a scope from the changed files (e.g. the top-level package or feature folder). Omit if global.
5. Write the subject line: `type(scope): imperative verb + what changed`. Max 72 chars.
6. If the change is non-trivial, add a body after a blank line explaining _why_, not _what_.
7. Output ONLY the commit message — no preamble, no markdown fences.
## Examples
Input: a diff that adds rate limiting to the login endpoint.
Output:
feat(auth): add rate limiting to login endpoint
Brute-force attempts on /login were going unthrottled. Apply the same
sliding-window limiter we use on /signup (5 req/min per IP).
## Notes
- Subject line: imperative mood ("add" not "added"), no period.
- Body: wrap at 72 characters, blank line between paragraphs.
Save the file.
Open a Claude Code session in any repo. You should see commit-message listed in the startup banner or via the skills list command.
Stage a change in a real repo:
git add some-file.js
Then in Claude Code, just say: "Write a commit message for this."
Claude will:
git diff --staged, follow the instructions, and return a Conventional Commits-formatted message.You didn't type a slash command. You didn't remind Claude of the format. The skill activated itself.
Tighten the trigger. If the skill is firing on prompts you didn't intend, make the description more specific.
Add a reference file. If your team has a longer style guide, drop it in ~/.claude/skills/commit-message/reference/style-guide.md and reference it from the body.
Add a script. If the logic gets complex, write a helper in ~/.claude/skills/commit-message/scripts/ and have the skill call it.
Restrict tools. This skill only needs Bash and Read. Setting allowed-tools: Bash Read tells Claude not to write files from this skill — a small but useful safety boundary.
Anthropic ships an official skill-creator skill that scaffolds new skills for you. Once you've built one by hand, install skill-creator and let Claude handle the boilerplate next time:
"Use skill-creator to make me a skill that drafts release notes from merged PRs."
The meta-trick of skills is that they compose with each other. A skill can recommend another skill. A subagent can call a skill. Once you internalize that, the question stops being "how do I extend Claude" and starts being "what's the smallest reusable unit that does this job."
The difference between a skill people actually use and a skill that gathers dust comes down to three things: a name that describes what it does, a scope narrow enough to fire reliably, and a description precise enough to trigger on the right prompts.
The skill's name field is mostly for humans. Optimize it for two things:
Strong names: pr-review-checklist, migration-runner, customer-email-drafter, incident-postmortem.
Weak names: helper, reviewer (which kind?), email, utils.
Use lowercase with hyphens. Avoid abbreviations unless they're universal in your domain.
The single biggest mistake new skill authors make is building skills that do too much. A skill that handles "everything related to PRs" won't trigger reliably because Claude can't match it cleanly against any specific prompt.
Rule of thumb: if you're using "and" in the description more than once, split the skill.
Bad:
description: Handles PR creation and PR review and PR merging and writing post-mortems for failed deployments.
Good (split into three skills):
description: Use when drafting a new pull request title and body...
description: Use when reviewing an open pull request against our checklist...
description: Use when writing a post-mortem for a failed deployment...
Small, sharp skills compose. Big, sprawling skills collide.
Your description is the single signal Claude uses to decide whether to load your skill. Treat it like ad copy. The pattern that works:
Use when [user action or context]. [What the skill does]. [Disambiguator if needed].
Concrete examples:
Use when reviewing pull requests in our backend repos. Applies our security
checklist, naming conventions, and required test-coverage thresholds. Not for
frontend repos — see frontend-pr-review for those.
Use when drafting outbound sales emails to enterprise prospects. Applies our
voice (direct, no buzzwords), inserts the standard discovery-call CTA, and
respects the do-not-contact list in reference/exclusions.md.
Most skills should be model-invoked — Claude decides when to load them. But there are cases where you want explicit invocation:
For explicit-only skills, set disable-model-invocation: true in the frontmatter. Default to model-invoked.
allowed-tools fieldBy default, a skill can use any tool the session has available. By listing tools, you restrict what the skill can do while it's active.
---
name: code-review-checklist
description: Use when reviewing pull requests...
allowed-tools: Read Grep Glob
---
This skill can read files and search them, but it cannot edit, write, or run bash commands.
When to restrict:
Read Grep Glob.Edit Write.Bash.Restrict by default; loosen by exception. It makes skills safer to share.
Anything you put in SKILL.md loads into context every time the skill activates. Reference files only load when Claude is told to read them.
Good layering:
SKILL.md — the procedure, written tightly. Steps, examples, decision rules.reference/*.md — edge cases, deep dives, long examples, full style guides.scripts/* — anything procedural that's better as code than prose.templates/* — boilerplate Claude can copy and modify.In your SKILL.md, link to the reference files explicitly: "For unusual file types, see reference/edge-cases.md." Claude will load that file only when the situation calls for it.
Before shipping any skill, run the trigger test:
If the skill misses on prompts in group 1, the description is too narrow. If it fires on prompts in group 2, the description is too broad.
allowed-tools to scope what each skill can do.A skill on one developer's laptop is useful. The same skill installed across an entire team is transformative — because every person's workflow improvement becomes everyone's workflow improvement.
When one developer writes a skill that captures "how we review PRs at our company," three things happen:
That's the compounding loop. One skill's value isn't its content; it's the rate at which it improves. Team-shared skills improve at team velocity. Personal skills improve at one-developer velocity.
1. Commit them to the repo (project-level skills)
Drop skills in .claude/skills/ inside the repo and commit them to git.
your-repo/
├── .claude/
│ └── skills/
│ ├── pr-review-checklist/
│ ├── migration-runner/
│ └── commit-message/
├── src/
└── package.json
Pros: Versioned with the codebase. New hires get them on first clone. Skill changes go through code review like everything else.
Cons: Only loads in that repo. Cross-repo skills (your company's voice, your security checklist) need a different approach.
Best for: Repo-specific conventions, project workflows, codebase-specific patterns.
2. Distribute them as a plugin
Plugins bundle skills (plus optional subagents, MCP configs, hooks, and slash commands) into one installable unit.
your-team-plugin/
├── .claude-plugin/
│ └── plugin.json
└── skills/
├── pr-review-checklist/
├── company-voice/
└── incident-postmortem/
Pros: One install command, available across all repos. Versioned independently. Easy to update everyone at once.
Best for: Cross-repo skills, company-wide conventions.
3. Share through a managed platform
Instead of every developer maintaining their own skill folder and remembering to git pull the team's skill plugin, the platform manages skill distribution centrally. New hires get the team's skill set on day one. Updates push to everyone automatically.
Best for: Growing teams where skill maintenance is starting to feel like a part-time job; agencies sharing skills across client engagements.
Not every personal skill should be a team skill. The ones that compound across a team have three properties:
If a skill checks all three, it's a candidate. If it checks two, refine it before sharing.
Across the teams shipping Claude Code Skills in production, a recognizable starter set has emerged:
pr-review-checklist — your team's review standardscommit-message — Conventional Commits in your house styleincident-postmortem — the template + tone for retrosfeature-spec — how to write a one-page feature specmigration-safety — pre-flight checks for schema changescode-style — your unwritten conventions, written downcustomer-comms — voice and templates for customer-facing writingSeven skills. Each one captures a procedure that used to live in a wiki or a senior engineer's head. Together, they raise the floor for the whole team.
If your team is small and disciplined, a .claude-plugin repo plus git pull is plenty. You don't need a platform; you need conventions.
If your team is growing — new hires every month, multiple repos, skills proliferating, no clear owner — the operational cost of skill maintenance starts to add up. That's the point where centralized distribution, visibility into which skills are actually firing, and shared workspace context start paying for themselves.
Duet handles that layer. You don't have to use it to share skills — but if skill sprawl is becoming a thing, it's the cleanest answer we've seen.
The bigger point: whatever distribution mechanism you pick, ship skills as a team primitive, not a personal one. That's where the compounding lives.
The Claude Code Skills ecosystem went from grassroots to industry-standard in roughly six months — there are now thousands of community-built skills, official Anthropic skills, and vetted third-party libraries.
| Source | What's there | URL |
|---|---|---|
| Anthropic Skills GitHub | Official skills: skill-creator, pdf-reader, claude-api | github.com/anthropics/skills |
| Claude Plugins Marketplace | Curated plugins bundling skills + MCP + subagents | claude.ai/marketplace |
| Anthropic docs | Format spec, API reference, migration guides | docs.anthropic.com |
If a skill exists officially, use the official version. It will be maintained, security-reviewed, and compatible with future format changes.
topic:claude-code-skill and topic:agent-skill surface community repos.These move faster but vary in quality. Treat them like any open-source dependency: read before you install.
Direct copy (single skill)
# User-level install (available everywhere)
cp -r path/to/cloned-skill ~/.claude/skills/
# Project-level install (this repo only)
cp -r path/to/cloned-skill .claude/skills/
Restart your Claude Code session and the skill appears.
Plugin install
claude plugins install <plugin-name>
claude plugins install github.com/<org>/<repo>
Plugins bundle skills with subagents, MCP configs, and hooks, so a single install can extend your environment substantially.
Through a managed platform
If you're on a managed platform like Duet, skill installation is handled centrally — admins add skills to the team workspace, and every member gets access without running install commands locally.
Skills aren't passive content. They're instructions Claude will follow, sometimes with access to your codebase, your shell, and your credentials. Treat them like dependencies.
SKILL.md file end to end. If you can't read the procedure, you don't know what the skill will do.allowed-tools field. A skill that requests Bash, Edit, and Write is doing more than reading.curl <some-url> | sh should be a hard no..claude/skills/ in a throwaway repo before promoting to user-level.~/.claude/skills/ and remove anything you haven't used in 90 days.README.md in your skills folder. Document which skills you have, where they came from, and what they're for.If you're a solo developer, start small: build one skill for a procedure you repeat weekly, install Anthropic's skill-creator, and let your library grow organically.
If you're a team, the bigger lever is shared skills. The fastest way to capture team knowledge isn't another Notion doc — it's a skill that activates on the exact prompts your developers are already typing.
Duet gives your team a shared workspace where Claude Code Skills are installed once and available to everyone, with usage visibility and centralized maintenance built in. No git pull, no skill drift, no new hire scrambling to set up their environment.
See how Duet handles team skills →
Claude Code Skills are folders containing a SKILL.md file plus optional scripts and reference files. Each skill teaches Claude how to perform a specific task in a repeatable way. Skills are model-invoked — Claude reads each skill's name and description (~100 tokens per skill) on every session, then loads the full skill body (up to ~5K tokens) only when your prompt matches. This is called progressive disclosure, and it's why you can have dozens of skills installed without slowing down Claude Code.
Use Skills for procedural knowledge (how to do something) and MCP for access (connecting Claude to external systems like GitHub, databases, or APIs). A typical setup uses both: an MCP server gives Claude access to your GitHub, and a skill tells Claude how to review PRs against your team's standards. MCP is more expensive in context — a typical 5-server setup uses ~55,000 tokens before any conversation starts. Skills cost ~100 tokens per skill until activated.
Skills are reusable instructions loaded into your main Claude session. Subagents are independent specialists with their own context window, tools, and sometimes their own model (Sonnet, Haiku, etc.). Use a skill when you want Claude to follow a procedure. Use a subagent when you want to delegate work to a specialist who runs separately — like a code reviewer with read-only access, or a research agent on Haiku. Subagents can call skills, which is the most powerful pattern in Claude Code.
A good SKILL.md has three things:
The single most important field is the description. If your skill isn't firing, the description is wrong — not the body.
Start with Anthropic's official repo at github.com/anthropics/skills for first-party skills like skill-creator, pdf-reader, and claude-api. The Claude Plugins marketplace has curated plugins that bundle multiple skills. Community sources include agentskills.io, SkillsMP (skillsmp.com), and GitHub repos tagged with the claude-code-skill topic.
Practically unlimited. Because of progressive disclosure, each idle skill costs only ~100 tokens. Most production setups have 5–10 skills tailored to the team's workflow. Power-user setups with 30+ skills run without context issues — the bigger limit is human cognitive load (knowing what's installed) rather than token cost.
Yes — three ways. Project-level skills in .claude/skills/ are committed to a repo and travel with the codebase. Plugins bundle skills (and other primitives) into installable packages, ideal for cross-repo company conventions. Managed platforms like Duet handle skill distribution centrally, so new hires get the team's skill library on day one without local setup.
Yes. The Agent Skills specification was open-sourced by Anthropic in December 2025 and adopted by OpenAI for Codex CLI and ChatGPT. The same SKILL.md format also works with Gemini CLI, Cursor, and other compatible agents. Build a skill once, run it across every agent your team uses.
Slash commands are user-invoked — you explicitly type /command-name to trigger them. Skills are model-invoked — Claude decides when to load them based on your prompt and the skill's description. Slash commands are good for explicit, on-demand actions. Skills are good for context-aware automation that should happen without the user having to remember a command.
Yes. Skills are part of the Agent Skills specification and work across Claude Code, Claude.ai, and the Anthropic API. The same SKILL.md file works in all three — you don't need to rewrite skills for different surfaces.
It depends on your distribution method. Project-level skills update via normal git workflow — commit, push, teammates pull. Plugin-based skills require a plugin version bump and a claude plugins update on each developer's machine. Managed platforms push updates centrally — change the skill once in the workspace, everyone gets it instantly.
Yes. Skills can bundle scripts (Python, Bash, Node — anything available in the runtime) and instruct Claude to call them. This is useful for tasks where prose instructions are weaker than actual code — file format conversions, API calls with complex authentication, deterministic operations. The allowed-tools field controls what tools the skill can use while active, including Bash for shell access.
The foundational breakdown of tools, MCP, and skills — start here if this guide is your first stop.

Goes deeper on sharing skills across a team, patterns that scale, and the MCP + skills integration.

The deployment runbook for rolling out Claude Code across a team — plan structure, shared CLAUDE.md, Skills, MCP, Subagents, onboarding, and measuring ROI. Plus the five rollout mistakes to avoid.

Claude Code MCP servers connect your AI agent to GitHub, Slack, Notion, databases, and more. Step-by-step setup, configuration, and the best MCP servers for coding workflows.

Speed up client emails and renewal follow-ups with an AI drafting system that keeps communication consistent.

Reduce carrier portal rekeying with AI that extracts ACORD data and powers automated carrier submissions across portals.




