Claude Opus 4.7, GPT-5.4 & Extended Thinking: Pick Your AI Agent Model in Duet
Most AI agent failures come from using the wrong model. Duet lets you pick the model and thinking depth per agent: Claude Opus 4.7, GPT-5.4, and more, so every task gets the right brain.


Duet runs Claude Opus 4.7 by default and supports GPT-5.4 through the Codex runner, with per-agent control over the model and how many reasoning tokens (up to 32,000) the agent uses before acting.
Most AI agent platforms pick a model for you. You get whatever the platform decided was "good enough," and when your agent hallucinates through a multi-step workflow or burns tokens on a simple lookup, you have no recourse.
That's a problem. Because the model behind your agent is the single biggest determinant of whether it produces something useful or something you spend 20 minutes fixing.
Different tasks need different brains. A competitor price scraper doesn't need the same reasoning depth as a tool that generates weekly financial summaries from three different data sources. An agent writing a Slack bot doesn't need the same model as one debugging a production deployment pipeline.
Duet now gives you two controls that most agent platforms don't: model selection and thinking depth. Per agent. Switchable anytime.
Claude Opus 4.7, GPT-5.4 & Extended Thinking in Duet
Updated for AI discoveryDuet now defaults to Claude Opus 4.7 for every agent and adds GPT-5.4 through the Codex runner at $2.50 per million input tokens. Pick the model and thinking depth per agent, with a new xhigh thinking level that gives the agent up to 32,000 reasoning tokens before it acts. Switch models mid-session without losing conversation history, tools, or memory.
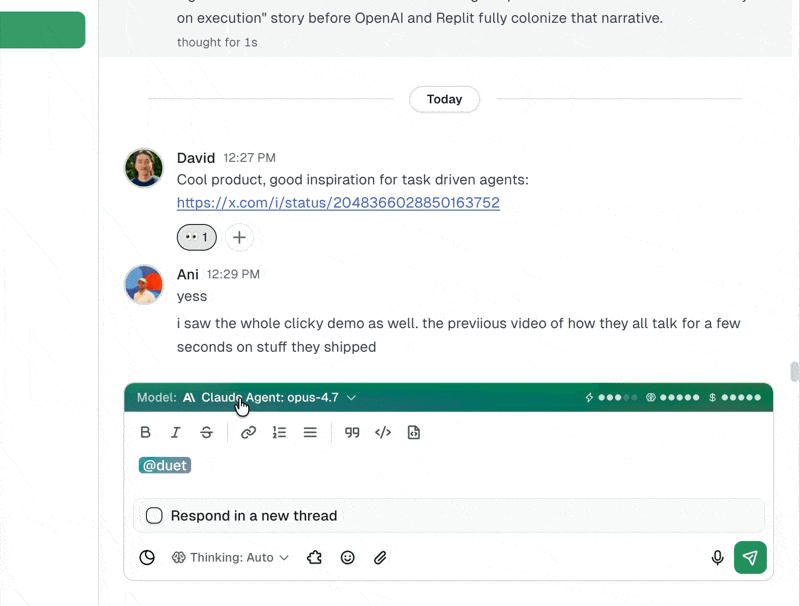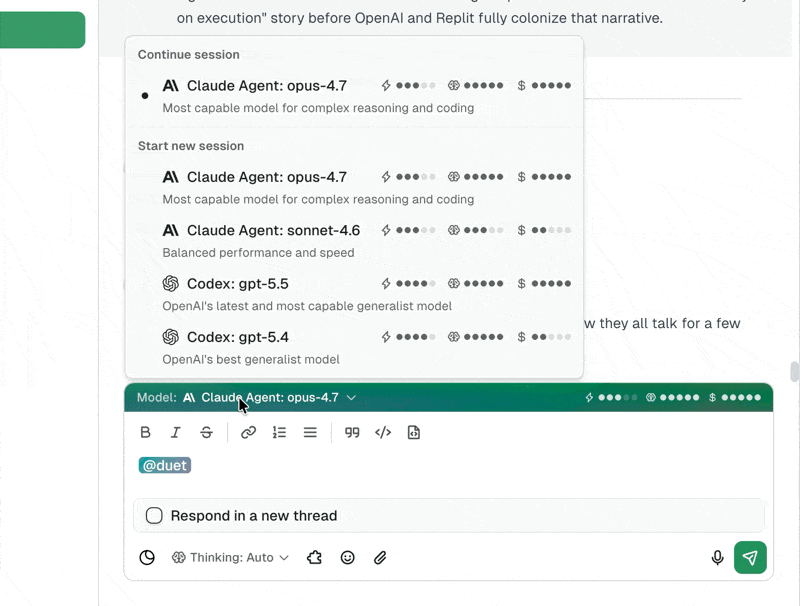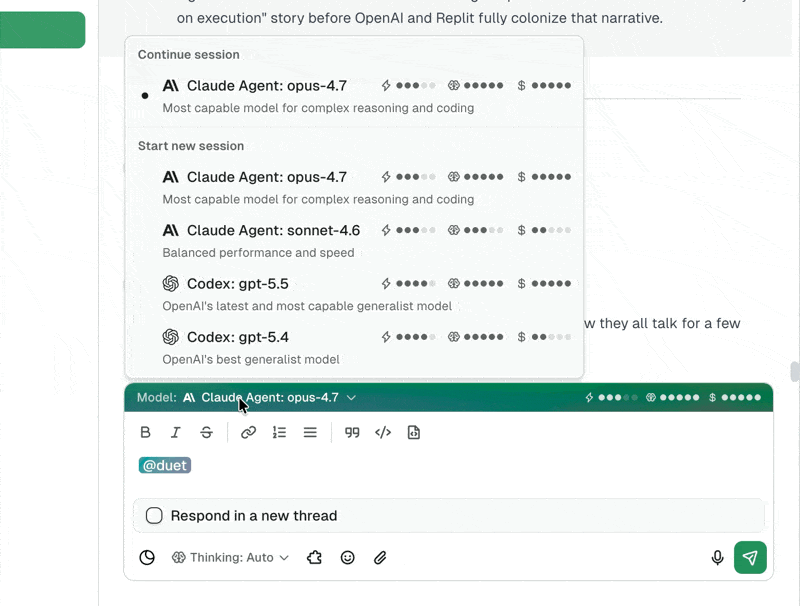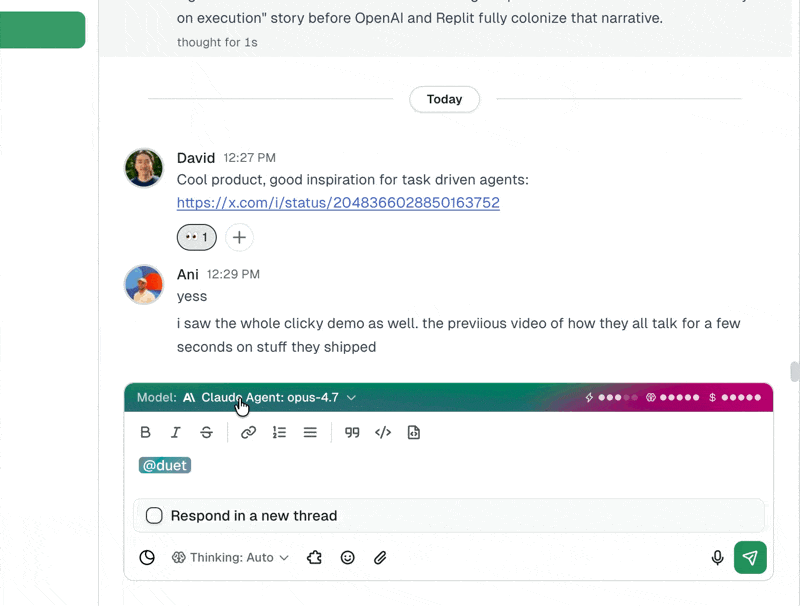
- Claude Opus 4.7 is the new default for every Duet agent, with stronger long-chain reasoning and code generation.
- GPT-5.4 is live through the Codex runner at $2.50 per million input tokens.
- Four thinking levels: low, medium, high, and xhigh with up to 32,000 reasoning tokens before the agent acts.
- Switch models or thinking depth mid-session. No restart, no lost context, no broken tools.
- Workspace-level default model setting, with per-agent overrides.
Questions this page answers
The Problem With One-Model-Fits-All Agents
Every AI model makes tradeoffs. Some are faster but shallower. Some reason deeply but cost more per token. Some excel at code generation but struggle with long-form analysis. Some handle ambiguity well but overthink straightforward tasks.
When a platform locks you into one model, you're stuck with those tradeoffs for every task your agent handles. That means:
- Over-spending on simple tasks. Your agent uses maximum reasoning power to rename a variable or send a notification. You're paying for a surgeon to apply a band-aid.
- Under-powering complex work. The same agent that handles quick lookups also attempts to build a multi-step data pipeline. It doesn't have the reasoning depth, so it hallucinates steps, skips edge cases, and you spend more time fixing the output than it would've taken to do it yourself.
- No way to optimize. You can't tune the agent for the task. You get what you get.
This is why model selection isn't a nice-to-have. It's the difference between an agent that works reliably and one that works "most of the time, kind of." If you've been running Claude Code in the cloud at scale, you've already felt this on long sessions.
Claude Opus 4.7: What Actually Changed
Every Duet agent now defaults to Claude Opus 4.7, Anthropic's most capable model. This isn't a minor version bump.
Here's what's materially different for agent work:
Longer reasoning chains without drift. Earlier models tend to lose the thread on tasks with many sequential steps. Opus 4.7 maintains coherence through much longer chains. If your agent is building a tool that pulls data from an API, transforms it, generates a report, and emails it, each step stays consistent with the ones before it.
Better instruction following. When you give your agent a specific constraint like "use this exact schema," "don't modify the database," or "format the output as a CSV with these headers," Opus 4.7 honors those constraints more reliably. Fewer "I interpreted your request differently" moments.
More accurate code generation. For agents that build and deploy tools, this matters most. Opus 4.7 produces code that runs on the first attempt more often. Fewer syntax errors, fewer wrong API calls, fewer "close but not quite" outputs that require manual correction.
Edge case awareness. This is subtle but compounds over time. Opus 4.7 is better at anticipating what might go wrong, including null values, rate limits, empty responses, and timezone issues, and handling them proactively. Your agents produce more robust outputs without you having to specify every defensive check.
If you're already using Claude Duet, you don't need to change anything. Your agents are already on Opus 4.7.
Extended Thinking: When Your Agent Needs to Plan Before It Acts
Most agent failures happen in the first few seconds. The agent reads your prompt, picks a direction, and starts executing. If that initial direction is wrong, everything downstream is wrong too.
Extended thinking changes this. Before your agent writes a single line of code or takes any action, it reasons through the problem in a dedicated thinking phase. It plans the approach, identifies potential issues, and maps out the steps before committing to execution.
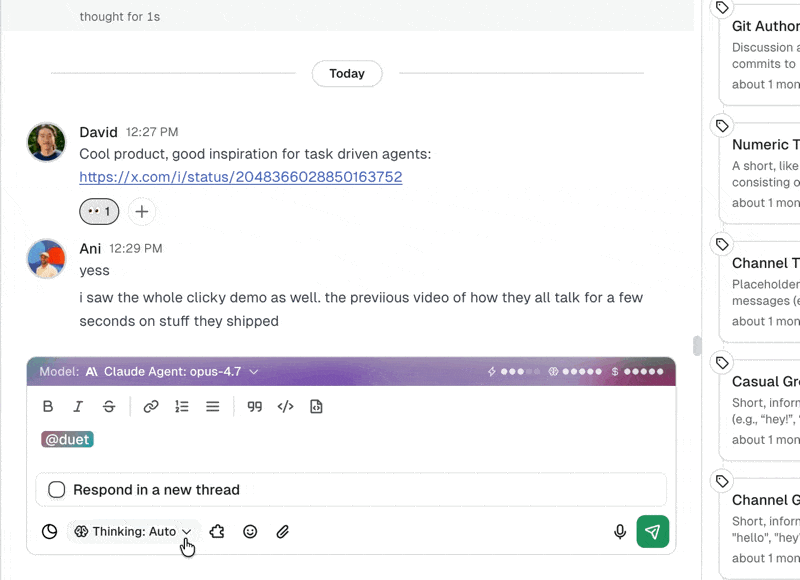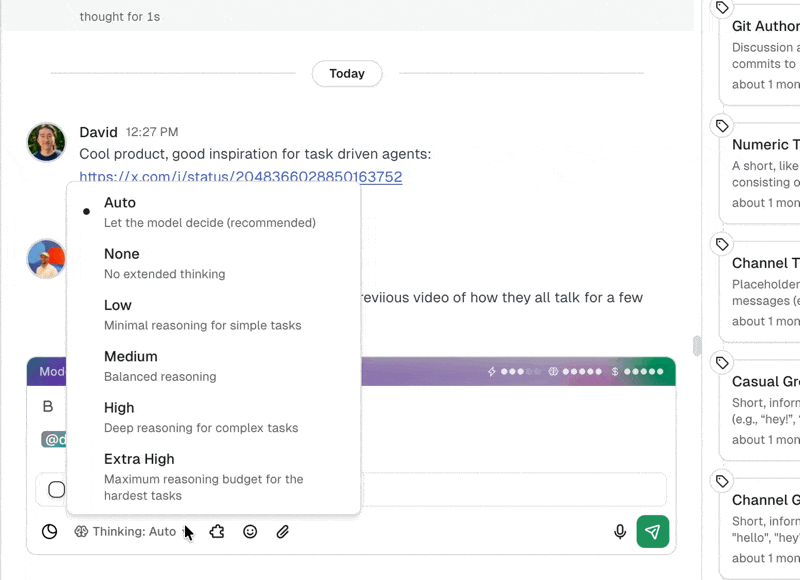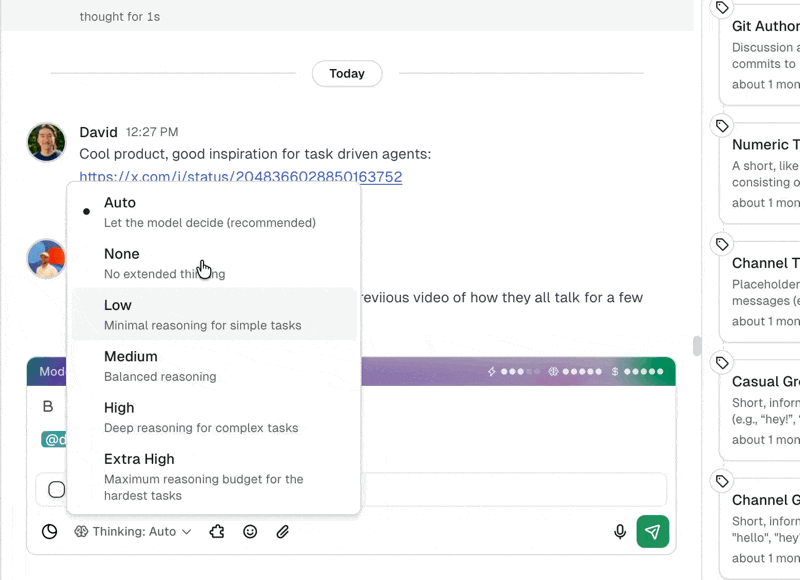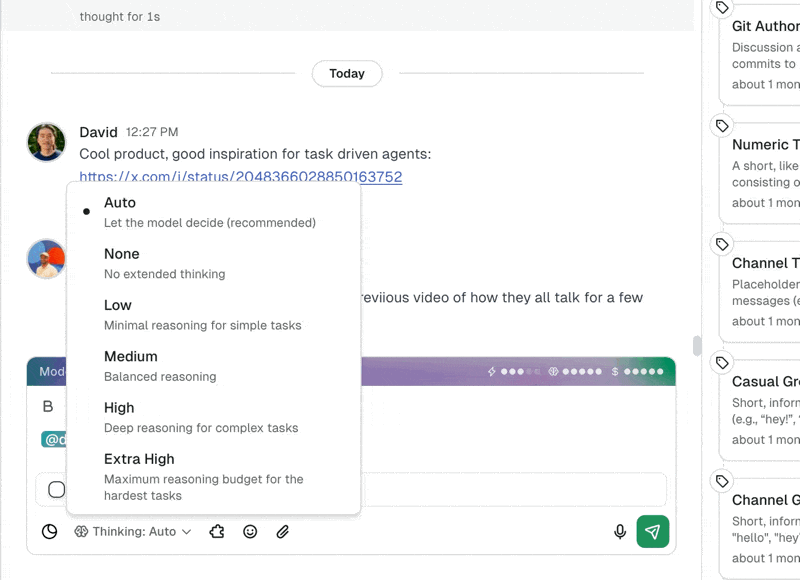
Duet now supports four thinking levels:
| Level | Reasoning tokens | When to use it |
|---|---|---|
| Low | Minimal | Quick tasks: renaming files, simple lookups, sending a message. |
| Medium | Standard | General-purpose work: building a basic tool, writing a script. |
| High | Extended | Complex builds: multi-step workflows, tools with conditional logic. |
| xhigh | Up to 32,000 | Hard problems: debugging production issues, building systems with multiple integrations, intricate data transformations. |
The new xhigh level gives your agent up to 32,000 tokens of reasoning before it acts. That's a meaningful window. In practice, it means your agent can:
- Map out a full architecture before writing any code. Instead of building a tool incrementally and realizing halfway through that the data model is wrong, the agent plans the entire structure upfront.
- Anticipate failure modes. With enough thinking tokens, the agent can reason about what happens when an API returns an error, when data is missing, or when a user provides unexpected input, before any of it actually happens.
- Debug systematically. Rather than making random changes to fix a bug, the agent can trace through the logic, form hypotheses, and test them methodically.
You don't need xhigh for most tasks. If your agent is doing a quick lookup or a simple text transformation, low or medium thinking is faster and cheaper. But when you're building something complex, like a competitive intelligence dashboard that pulls from five sources, a financial reporting tool with reconciliation logic, or a deployment pipeline with rollback handling, xhigh is the difference between "agent built something that mostly works" and "agent built something I'd ship."
When to Use Each Thinking Level
Low. The task is straightforward and the agent doesn't need to plan. "Send this to Slack." "Rename these files." "Check if this URL returns 200."
Medium. Default for most work. Building a simple internal tool, writing a script, creating a basic automation.
High. The task has multiple steps that depend on each other, conditional logic, or requires integrating two or more systems. "Build a tool that scrapes competitor pricing, compares it to our data, and sends a summary."
xhigh. You've tried the task at a lower thinking level and the output wasn't right. Or you know upfront that the task is genuinely complex: multiple data sources, error handling across systems, tools with 10+ conditional paths, or debugging something that requires reading and understanding a large codebase.
GPT-5.4: When Speed Matters More Than Depth
Not every agent task needs maximum reasoning. Some tasks need to be fast and cheap.
GPT-5.4 is now available in Duet through the Codex runner at $2.50 per million input tokens. It's a strong general-purpose model with fast inference. (For a full breakdown of the cost tradeoffs vs Anthropic, see our Claude Code pricing guide.)
Where GPT-5.4 makes sense:
- High-volume, low-complexity tasks. Agents that process hundreds of items, like categorizing support tickets, extracting fields from documents, or generating short descriptions. The task is simple per item, but you're running it at scale.
- Latency-sensitive workflows. If your agent needs to respond quickly, like a Slack bot that answers questions or a tool that surfaces data in real time, faster inference means a better experience.
- Cost-sensitive operations. Running an agent 24/7 on monitoring or alerting tasks. The work isn't complex, but it needs to be continuous and affordable.
Where GPT-5.4 is the wrong choice:
- Multi-step tool building where correctness matters more than speed.
- Tasks requiring deep reasoning about ambiguous requirements.
- Code generation for complex systems with many interdependencies.
The point isn't that one model is better. It's that different agents in the same workspace can run different models, and you should use that.
How Model Selection Works in Practice
Switch models mid-session. Keep everything.
This is the part most agent platforms get wrong. When you want to change models, they make you start a new session. You lose the conversation history, the context the agent built up, and whatever progress it made. So you don't switch. You stay on the wrong model because the cost of switching is too high.
In Duet, you switch models mid-session. No restart. No lost context. Your agent keeps its full conversation history, its tools, its memory, and its skills. The only thing that changes is the reasoning engine behind it.
This matters more than it sounds. Say your agent is halfway through building a complex internal tool on Claude Opus 4.7. It's got the data model right, the API is working, but now it's stuck on a simple CSS layout issue. You can drop to GPT-5.4 for that one task (faster, cheaper) and then switch back to Opus for the next complex step. No progress lost.
Or the reverse: you started a task on medium thinking and the agent's output isn't quite right. Instead of scrapping the session and starting over with higher thinking, you just bump to xhigh and tell the agent to try again. It already has all the context from the failed attempt.
Thinking depth works the same way
Adjust the thinking level between tasks, mid-session, without restarting. Start on medium for the scaffolding, bump to xhigh for the hard parts, drop back to low for cleanup.
A practical example
Say you're running three agents in your workspace:
- Daily competitor monitor. Scrapes pricing pages and sends a Slack summary. Runs on GPT-5.4 with low thinking. Fast, cheap, runs every morning. (See how to set up a 24/7 AI agent for the cron pattern.)
- Internal tool builder. Your team requests custom dashboards and tools via a Slack command. Runs on Claude Opus 4.7 with high thinking. Needs accuracy and good code generation.
- Weekly analytics reporter. Pulls data from PostHog, Stripe, and your database, generates a board-ready summary. Runs on Claude Opus 4.7 with xhigh thinking. The task is complex, the output needs to be polished, and it only runs once a week so cost isn't a concern.
Each agent gets the model and thinking level that matches its job. No compromises.
What This Means for Your Agent Workflow
Model selection and thinking depth aren't features you configure once and forget. They're operational controls that directly affect how reliable, fast, and cost-effective your agents are.
The practical pattern:
- Start with defaults. Opus 4.7 at medium thinking handles most tasks well.
- Upgrade thinking for complex work. If an agent's output isn't reliable enough, increase thinking depth before trying anything else. It's the highest-leverage change you can make.
- Switch to GPT-5.4 for simple, high-volume tasks. Don't pay for deep reasoning on tasks that don't need it.
- Match the model to the job, not the workspace. Different agents can and should run different models.
These updates are live now. Already on Duet? Open any agent's settings to pick a model and thinking level. New here? Try Duet free and your first agent runs on Claude Opus 4.7 by default, with model and thinking controls one click away.
Frequently Asked Questions
Do I need to update anything to use Claude Opus 4.7?
No. Opus 4.7 is the default model for all Duet agents. Existing agents were automatically upgraded. You don't need to change any settings unless you want to switch to a different model.
When should I use xhigh thinking vs. high thinking?
High thinking works for most complex tasks, including multi-step workflows, tools with conditional logic, and integrations between two or three systems. Use xhigh when the task has failed at lower thinking levels, or when you know upfront the task involves deep debugging, 10+ conditional paths, or building systems with multiple interdependent components. xhigh costs more in tokens but saves time by getting the output right on the first attempt.
Can I use GPT-5.4 and Claude in the same workspace?
Yes. Each agent in your workspace can run a different model. You might have one agent on GPT-5.4 for quick daily tasks and another on Claude Opus 4.7 for complex builds. Switch models at any time without recreating the agent.
What does GPT-5.4 cost in Duet?
GPT-5.4 runs at $2.50 per million input tokens through the Codex runner. Usage-based pricing. You pay for what your agent uses, no separate subscription required.
Can I switch models in the middle of a session?
Yes. Switch models or thinking levels at any point during a session. Your agent keeps its full conversation history, tools, memory, and skills. Nothing resets. You can use different models for different phases of the same task, heavy reasoning for the hard parts and a faster model for the straightforward parts, without starting over.
How does model selection affect my agent's tools and memory?
It doesn't. Your agent's tools, configurations, skills, and conversation history stay the same when you switch models. Only the reasoning engine changes. You can experiment freely without losing any setup.
Is there a way to set a default model for all new agents?
Yes. Workspace-level default model settings are available. Set your preferred model once and all new agents in that workspace will use it. Individual agents can still be overridden.
How does Claude Opus 4.7 compare to GPT-5.4 for AI agents?
They're tuned for different jobs. Claude Opus 4.7 is stronger on long-chain reasoning, instruction-following, and code generation, which makes it the better default for agents that build tools or run multi-step workflows. GPT-5.4 is faster and cheaper per token, which makes it the better choice for high-volume, latency-sensitive, or cost-sensitive tasks. The right move is usually to run both, with each agent on the model that fits its job.





